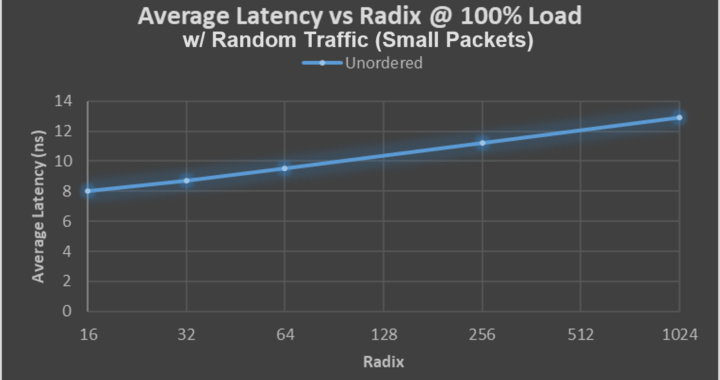
November 17, 2020 – Data Vortex Technologies announces the availability of the DV Load/Store Memory Semantic Switch IP Block. This parameterizable switch can be placed at multiple levels within choice AI, HPC, cloud and big graph data analytics hardware. Regardless of load or radix, the latency of the Data Vortex switch is approximately 10 nanoseconds. The nimble, disaggregated Data Vortex switch, which has been validated in hardware and benchmarked at several United States federal sites, can be recognized at data center scale in three critical areas connecting three core elements: Computer, Memory, and I/O. Implementation areas of the IP Block include:
- Using memory semantics at scale, a Data Vortex network efficiently supports disaggregation of the data center, allowing large, shared pools of memory. GPU and CPU resource can easily be allocated across the entire data center and by all users.
- The DV IP block can be implemented at the processor package level, as the Data Vortex can be used as a low latency chiplet interconnect switch, interconnecting chiplets of GPUs, CPUs, TPUs, memory controllers, and more.
- Lastly, the on-die network (Data Vortex Network on Chip) enables interconnecting many small compute elements. The DV network’s radix and size is parameterizable to suit users’ particular application needs and can be easily tiled in a physical ASIC mesh
This year, two new patents on core-to-core communication and improved data transfer for big data graph analytics, have been filed. Simulations of the IP Block were completed in September (partial results shown in graph above). Data Vortex Technologies is working with select buyers and licensees to ensure this intellectual property fits within existing and road-mapped product lines and address mission critical areas of need.
This release was published in:
EnterpriseAI – https://www.enterpriseai.news/2020/11/13/data-vortex-announces-memory-semantic-load-store-switch-for-ai-hpc-graph-analytics/